半角カタカナ・機種依存文字
半角カタカナに関しては総務省は
ユーザーのインターネット利用環境は様々です。ウェブサイトの制作者は、ユーザーが使用する端末の機種やOSなどの違いに依らず、ページ内容が正しく表示されるように制作しなければなりません。そこで今回は、多様な利用環境に配慮したテキストの使用方法について解説します。 対策方法 ポイント1 半角カタカナを使用しない 半角カタカナを使用するとブラウザ上で文字化けをおこす可能性があります。その為、全角の漢字、ひらがな、カタカナ、英数と半角の英数を使用しましょう。
こんなふうに書いています。
https://www.soumu.go.jp/soutsu/tokai/siensaku/accessibility/L3_text1.html
以下の機種依存文字はShift-JISを文字コードとして使っている場合です。

以下代表的な機種依存文字
丸数字

右下に点の付く数字
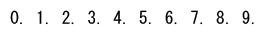
かっこ付き文字

トランプ絵文字
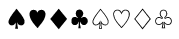
学術記号
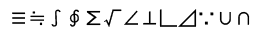
濁点付き文字
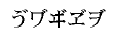
かっこ付き数字
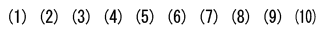
ローマ数字
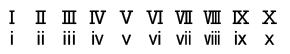
手型の矢印、左右2組セットの矢印、上下2組セットの矢印、太い矢印
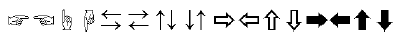
ナンバーやtelなどの省略文字、丸付き文字、年号の省略文字
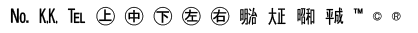
単位文字
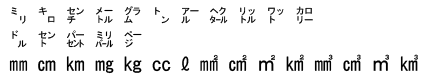
インターネットが普及し始めた当時、日本語の文字コードが、JIS、Shift-JIS、EUC、ユニコードとあり、Windowsが採用していたShift-JISで書かれたページが、ワークステーションのOSのUNIXで使われていた文字コードのEUC-JP、MacのShift-JIS、UTF-8では文字が化けるということがありました。(MacOSが漢字Talkと呼ばれていた頃の漢字コードは6.0.xまではShift-JISで、7.1からユニコード(UTF-8)になった) ※ワークステーションはメールサーバ、Webサーバーなどサーバーに多く使われいる。 文字化けを解消するために、文字変換を行うためのプロキシーサーバーというものもありました。
現在では、Webページ(ホームページ)はUTF-8体系を使っているなら、半角文字や機種依存文字を使っても文字化けに関しては問題ありませんが、デザイン的にどうなのかと思います。

どちらが見やすいですか?
漢字コードについて
コンピューターの内部では文字を数値として扱っています。アルファベットのAという文字は16進数で0x41(10進数だと65、0xはC言語やPerlでの16進数の表記法)が割り当てられています。アルファベット、数字、記号だけなら7ビットで表現できます。(アルファベット大文字、小文字で26×2、数字10、記号が31、改行、バックスペース、デリートなどの特殊文字(印刷できないが、いろいろな用途で使われる)が32あります。合計で125=7ビットです。
ASCII
ASCII(American Standard Code for Information Interchangeの略)1963年に現在のANSIが制定した、7ビット文字集合です。1967年の改定で現在の定義となりました。
| 上位4ビット | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 下 位 4 ビ ッ ト |
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
| 0 | NUL | DLE | SP | 0 | @ | P | ` | p | |
| 1 | SOH | DC1 | ! | 1 | A | Q | a | q | |
| 2 | STX | DC2 | " | 2 | B | R | b | r | |
| 3 | ETX | DC3 | # | 3 | C | S | c | s | |
| 4 | EOT | DC4 | $ | 4 | D | T | d | t | |
| 5 | ENQ | NAK | % | 5 | E | U | f | u | |
| 6 | ACK | SYN | & | 6 | F | V | e | v | |
| 7 | BEL | ETB | ' | 7 | G | W | g | w | |
| 8 | BS | CAN | ( | 8 | H | X | h | x | |
| 9 | HT | EM | ) | 9 | I | Y | i | y | |
| A | LF | SUB | * | : | J | Z | j | z | |
| B | VT | ESC | + | ; | K | [ | k | { | |
| C | NP | FS | , | < | L | ?\ | l | | | |
| D | CR | GS | - | = | M | ] | m | } | |
| E | SO | RS | . | > | N | ^ | n | ~ | |
| F | SI | US | / | ? | O | _ | o | DEL | |
※赤字は制御文字(印刷されない)BS:バックスペース HT:ホリゾンタルタブ(水平タブ)DEL:デリート SP:半角スペースなど
ISO/IEC 646(ASCIIの国際規格)
ASCIIの規約を取り込みながら、1967年にISOが制定した国際規格です。
| 上位4ビット | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 下 位 4 ビ ッ ト |
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
| 0 | NULL | DLE | SP | 0 | @ | P | ` | p | |
| 1 | SOH | DC1 | ! | 1 | A | Q | a | q | |
| 2 | STX | DC2 | " | 2 | B | R | b | r | |
| 3 | ETX | DC3 | # | 3 | C | S | c | s | |
| 4 | EOT | DC4 | $ | 4 | D | T | d | t | |
| 5 | ENQ | NAC | % | 5 | E | U | e | u | |
| 6 | ACK | SYN | & | 6 | F | V | f | v | |
| 7 | BEL | ETB | ' | 7 | G | W | g | w | |
| 8 | BS | CAN | ( | 8 | H | X | h | x | |
| 9 | HT | EM | ) | 9 | I | Y | i | y | |
| A | LF | SUB | * | : | J | Z | j | z | |
| B | VT | ESC | + | ; | K | [ | k | { | |
| C | FF | FS | , | < | L | ¥ | l | | | |
| D | CR | GS | - | = | M | ] | m | } | |
| E | SO | RS | . | > | N | ^ | n | ~ | |
| F | SI | US | / | ? | O | _ | o | DEL | |
Shift-JISに関連した符号化方式には以下があります。
| 符号化方式 | 説明 |
|---|---|
| MS漢字コード (CP932) |
マイクロソフトが1982年に定めた文字コード。JIS C 6226-1798で定義される文字集合を、 半角カタカナが使用する0xA1~0xDF、およびDEL(0x7F)の領域を避けるように巧みにシフ トさせたもの。ただし、未使用の領域に各社が独自文字を割り当て、「NEC版CP932」や 「IBM版CP932」が現れるなど、混乱が生じていた |
| Windows-3.1J (MS932) |
マイクロソフトが1993年に定めた文字コード。上記混乱を収拾するために各社独自の実装の 内、広く使用されているものだけを仕様に取り込み、以後各社独自の実装を禁止したもの。 JIS X 0208をベースとし、13区に83字の「NEC特殊文字」を89~92区に374字の「NEC選 定IBM拡張文字」を、115~119区に388字の「IBM拡張文字」を追加しています。 |
| Shift-JISX02013 | JIS Xn0213に対応したもの |
| Shift-JIS-2004 | JIS X 0213:2004の改定に対応したもの |
色付きの部分は推奨文字で各言語で別の文字を割り当ててもよいと規定されました。
JIS X 0201(半角英数・半角カナ)
ISO/IEC 646を日本向けにカスタマイズし、1969年にJISが制定されました。ASCIIとの違いは以下の色付きの部分バックスラッシュ(\)が円記号(\)にチルダ(~)がオーバーライン(‾)になっているところが相違点です。また、8ビット空間を用いて半角カタカナを定義しています。
| 上位4ビット | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 下 位 4 ビ ッ ト |
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 0 | NUL | DLE | SP | 0 | @ | P | ` | p | ー | タ | ミ | ||||||
| 1 | SOH | DC1 | ! | 1 | A | Q | a | q | 。 | ア | チ | ム | |||||
| 2 | STX | DC2 | " | 2 | B | R | b | r | 「 | イ | ツ | メ | |||||
| 3 | ETX | DC3 | # | 3 | C | S | c | s | 」 | ウ | テ | モ | |||||
| 4 | EOT | DC4 | $ | 4 | D | T | d | t | 、 | エ | ト | ヤ | |||||
| 5 | ENQ | NAK | % | 5 | E | U | f | u | ・ | オ | ナ | ユ | |||||
| 6 | ACK | SYN | & | 6 | F | V | e | v | ヲ | カ | ニ | ヨ | |||||
| 7 | BEL | ETB | ' | 7 | G | W | g | w | ア | キ | ヌ | ラ | |||||
| 8 | BS | CAN | ( | 8 | H | X | h | x | イ | ク | ネ | リ | |||||
| 9 | HT | EM | ) | 9 | I | Y | i | y | ウ | ケ | ノ | ル | |||||
| A | LF | SUB | * | : | J | Z | j | z | エ | コ | ハ | レ | |||||
| B | VT | ESC | + | ; | K | [ | k | { | オ | サ | ヒ | ロ | |||||
| C | NP | FS | , | < | L | \ | l | | | ャ | シ | フ | ワ | |||||
| D | CR | GS | - | = | M | ] | m | } | ュ | ス | ヘ | ン | |||||
| E | SO | RS | . | > | N | ^ | n | ‾ | ヨ | セ | ホ | ゙ | |||||
| F | SI | US | / | ? | O | _ | o | DEL | ツ | ソ | マ | ゚ | |||||
ISO-2022-JP(JISコード)
電子メール(E-mail)で使う符号化方式です。俗にいうJISコード。EUCで始まるエスケープシーケンスで、その後に続く文字集合を指定します。E-mailで文字化けするのは漢字コードが違っている、半角カタカナを使っている、絵文字を使っている等様々です。
| A | B | C | (漢字) | あ | い | う | (ASCII) | X | Y | Z |
| 41 | 42 | 43 | 1B 24 42 | 24 22 | 24 24 | 24 26 | 1B 28 42 | 58 | 59 | 5A |
エスケープシーケンスには下記があります。
| 規格 | 記号表記 | 16進表記 | 意味 |
|---|---|---|---|
| ISO-2022-JP | ESC ( B | 1B 28 42 | ASCII |
| ESC ( J | 1B 28 4A | JIS X 6220(JIS X 0201)-1976 ラテン文字集合 | |
| ESC $ @ | 1B 24 40 | JIS C 6226(JIS X 0208)-1978(通称:旧JIS) | |
| ESC $ B | 1B 24 42 | JIS X 0208-1983(通称:新JIS) または JIS X 0208-1990 | |
| ISO-2022-JP-1で追加 | ESC $ ( D | 1B 24 28 44 | JIS X 0212-1990(JIS補助漢字) |
| ISO-2022-JP-2で追加 | ESC $ A | 1B 24 41 | GB 2312-80(中国語) |
| ESC $ ( C | 1B 24 28 43 | KS X 1001-1992(韓国語) | |
| ESC . A | 1B 2E 41 | ISO/IEC 8859-1 の右半分 | |
| ESC . F | 1B 2E 46 | ISO/IEC 8859-7 の右半分 | |
| ISO-2022-JP-3で追加 | ESC $ ( O | 1B 24 28 4F | JIS X 0213:2000の1面 |
| ESC $ ( P | 1B 24 28 50 | JIS X 0213:2000の2面 | |
| ISO-2022-JP-2004 | ESC $ ( Q | 1B 24 28 51 | JIS X 0213:2004の1面 |
| ISO-IR 013 | ESC ( I | 1B 28 49 | JIS X 0201(半角カナ) ... 一部のソフトでのみ利用 |
ISO-2022-JPに類似した符号化方式
| 規格 | 説明 |
|---|---|
| CP50220 | Microsoftによる規格 ISO-2022-JPのWindows 3.1J版。半角カナをJIS x 0208 の全角カタカナに変換して表します。 |
| CP50221 | CP50220と類似していますが、半角カナをESC ( Iでエスケープして表します。 |
| CP50222 | CP50220と類似していますが、SO(0X1E)で半角カナの始まり、SI(0x0F)で終わりを示します。 |
| ISO-2022-JP-MS | Linux陣営が規定した独自規格。半角カナはESC ( I、外字をESC $ ( Iでエスケープします。 |
EUC-JP
Extended UNIX Code Packed Format for Japaneseの略。UNIX/Linux系のシステムで使用される符号化方式です。ASCIIとJIS X 0208(漢字)、JIS X 0201(半角カナ)を扱います。(JIS X 0208は説明していませんのでリンクをたどってください。)
Shift-JIS
Windows系で使用される符号化方式です。JIS X 0208の附属書で「シフト符号化表現」という名称で定義されています。半角文字(制御文字・英数記号・半角カナ)はJIS X 0201の文字をそのまま使用し、全角文字は1バイト目をJIS X 0201で未使用の0x81~0x9F、0xE0~0xEF、2バイト目を0x40~0x7E、0x80~0xFCの領域に計算式でシフトして符号化します。俗に言う「MS漢字コード」MicrosoftがMS-DOSなどで日本語を8ビット環境でも使えるようにシフトさせたことからShift-JISと呼ばれています。また、Microsoftが独自に拡張した文字が含まれています。Windowsなどで採用されたWindowsで広く使われるMS932という形式。Windows11はUTF-8を採用しています。
| 規格 | 説明 |
|---|---|
| CP50220 | Microsoftによる規格 ISO-2022-JPのWindows 3.1J版。半角カナをJIS x 0208 の全角カタカナに変換して表します。 |
| CP50221 | CP50220と類似していますが、半角カナをESC ( Iでエスケープして表します。 |
| CP50222 | CP50220と類似していますが、SO(0X1E)で半角カナの始まり、SI(0x0F)で終わりを示します。 |
| ISO-2022-JP-MS | Linux陣営が規定した独自規格。半角カナはESC ( I、外字をESC $ ( Iでエスケープします。 |
| A | B | C | あ | い | う | ア | イ | ウ |
| 41 | 42 | 43 | 82 A0 | 82 A2 | 82 A4 | B1 | B2 | B3 |
文字の割当は以下のようになります。
| 1バイト目 | 2バイト目 | 説明 |
|---|---|---|
| 0x0~0x1F | 制御文字 | |
| 0x20~0x7E | 英数記号文字 | |
| 0x7F | 制御文字(DEL) | |
| 0x81~0x9F | 0x40~0x7E、0x80~0xFC | JIS X 0213(1面:前半) |
| 0xA1~0xDF | 半角カナ | |
| 0xE0~0xEF | 0x40~0x7E、0x80~0xFC | JIS X 0213(1面:後半) |
| 0XF0~0xFC | 0x40~0x7E、0x80~0xFC | JIS X 0213(2面) |
Unicode
世界中の文字を1つのコード体系で表現しようとして制定されたものです。日本で定義された文字も取り込まれていますが、CJK(中国語・日本語・韓国語)で字形の似たものを統一するなどしています。Unicode文字の一覧
UTF-8
Unicode体系で一番利用されている符号化方式です。ASCII文字を1バイトで表現できるように、U+007Fまでの文字は1バトで、U+07FFまでの文字は2バイト、U+FFFF前の文字は3バイト、U+10000~U+10FFFFの文字は、本来のUTFF-8では4バイトに変換していますが、一部のシステムでは6バイトに変換することもあります。(サロケートペア(CESU-8)といいますが、難しいので説明は省略します。UTF-8ではほとんどサロケートペアは使わなくても表現できます。)
※U+xxxxxのUは16進数であることを表します。
| 範囲 | ビット数 | 変換元ビット | 変換後ビット |
|---|---|---|---|
| U+0000~U+007F | 7bits | 0xxxxxxx | 0xxxxxxx (00-7F) |
| U+0080~U+07FF | 11bits | 00000yyy xxxxxxxx | 110yyyxx 10xxxxxx (C0-DF) (80-BF) |
| U+0800~U+FFFF | 16bits | yyyyyyyy xxxxxxxx | 1110yyyy 10yyyyxx 10xxxxxx (E0-EF) (80-BF) (80-BF) |
| U+10000~U+10FFFF (本来のUTF-8方式) |
21bits | zzzzz yyyyyyyy xxxxxxxx | 11110zzz 10zzyyyy 10yyyyxx 10xxxxxx (F0-F7) (80-BF) (80-BF) (80-BF) |
| U+10000~U+10FFFF (CESU-8方式 サロケートペア) |
21bits | zzzzz yyyyyyyy xxxxxxxx ↓ (wwww = zzzzz-1) High:110110ww wwyyyyyy Low: 110111yy xxxxxxxx |
High:11101101 1010wwww 10yyyyyy (CD) (A0-AF) (80-BF) Low: 11101101 1011yyxx 10xxxxxx (CD) (B0-BF) (80-BF) |
※UTF-8とUTF-8N
UTF-8NはBOMなしのUTF-8。BOMとはByte Oder Markの略でUnicodeで符号化したテキストの先頭に付与される数バイトのデータ(UTF-8の場合:0xEF 0xBB 0xBFのs3バイト)です。
Webページ(ホームページ)で使用されるHTMLファイルはBOM無しで保存・上書きするほうが良いとされています。(BOM付きだと正常に処理できないことがあるからです。詳細は略します。興味がある方は検索してみてください。)
UTF-16、UTF-32
詳しく説明しませんが、UTF-16は16ビットで表現します。21ビットはサロケートペアを用います。UTF-32はUnicodeで定義されるすべての文字を32ビットで表現します。メモリ効率が良くないのであまり使われていません
※サロケートペア:2バイトで定義された基本多言語面に含まれない拡張領域の文字を、2バイトのバイト列二つを組み合わせて、計4バイトで表す。
バイトオーダー
16ビットや32ビットの値をファイルやネットワークに書き出す際に、上位バイトから書き出す方式(ビッグエンディアン BE)と下位バイトから書き出す方式(リトルエンディアン LE)があります。例えば「あ(U+3042)」をUTF-16で符号化し、ビッグエンディアンで書き出すと 0x30 0x42の順になります。リトルエンディアンで書き出すと 0x42 0x30の順になります。
ネットワークではビッグエンディアンが使われています。ファイルではWindows系が x86系CPUが効率的にあつかえるリトルエンディアンが主流となっています。UTF-8にはバイトオーダーの概念はありません。
BOM(バイトオーダーマーク)
UTF-16やUTF-32のバイトオーダーを示すために、ファイルの先頭にオプションとして付加する、数バイトのデータです。
| 符号化方式 | BOMの有無 | エンディアン | BOM | 備考 |
|---|---|---|---|---|
| UTF-8 | 省略可 | - | 0xEF 0xBB 0xBF | UTF-8 にはエンディアンの概念が無いがつけることがある。 |
| UTF-8N | 無し | - | BOM無しの UTF-8 を UTF-8N と呼ぶ。 | |
| UTF-16 | 省略可 | BE | 0xFE 0xFF | 省略時はビッグエンディアン推奨。 |
| LE | 0xFF 0xFE | |||
| UTF-16BE | 無し | BE | 利用者間で予め合意しておく。 | |
| UTF-16LE | 無し | LE | 利用者間で予め合意しておく。 | |
| UTF-32 | 省略可 | BE | 0x00 0x00 0xFE 0xFF | 省略時はビッグエンディアン推奨。 |
| LE | 0xFF 0xFE 0x00 0x00 | |||
| UTF-32BE | 無し | BE | 利用者間で予め合意しておく。 | |
| UTF-32LE | 無し | LE | 利用者間で予め合意しておく。 |
Windows11になって、文字コードがUTF-8になったのであまり文字化けすることはなくなりましたが、半角カタカナには十分注意してください。